Дата публікації: 21 квітня 2026
Автор: Олекс Гарний
Сьогодні пошук перестав бути сухим списком посилань — він розуміє контекст, наміри й навіть тон запиту. У цій статті я поясню, як працює пошук на основі штучного інтелекту, крок за кроком розберу ключові компоненти й покажу, що важливо знати власникам сайтів та розробникам.
Матеріал підходить як для технічно підкованих читачів, так і для людей, які просто хочуть краще розуміти, чому результати пошуку інколи дивують. Ділюся практичними порадами й прикладами з власної роботи, щоб усе було зрозуміло й корисно.
Що змінилося в пошуку за останні роки
Раніше пошукові системи працювали головно на збігу ключових слів і простих правилах ранжування. Тепер алгоритми вміють «розуміти» зміст сторінки, підбирати релевантні відповіді з урахуванням семантики і користувацького наміру.
Це переродження стало можливим завдяки розвитку моделей обробки природної мови та векторних уявлень тексту. Результат — швидший доступ до точних відповідей, краща підтримка запитів розмовного стилю і можливість знаходити інформацію за сенсом, а не лише за словами.
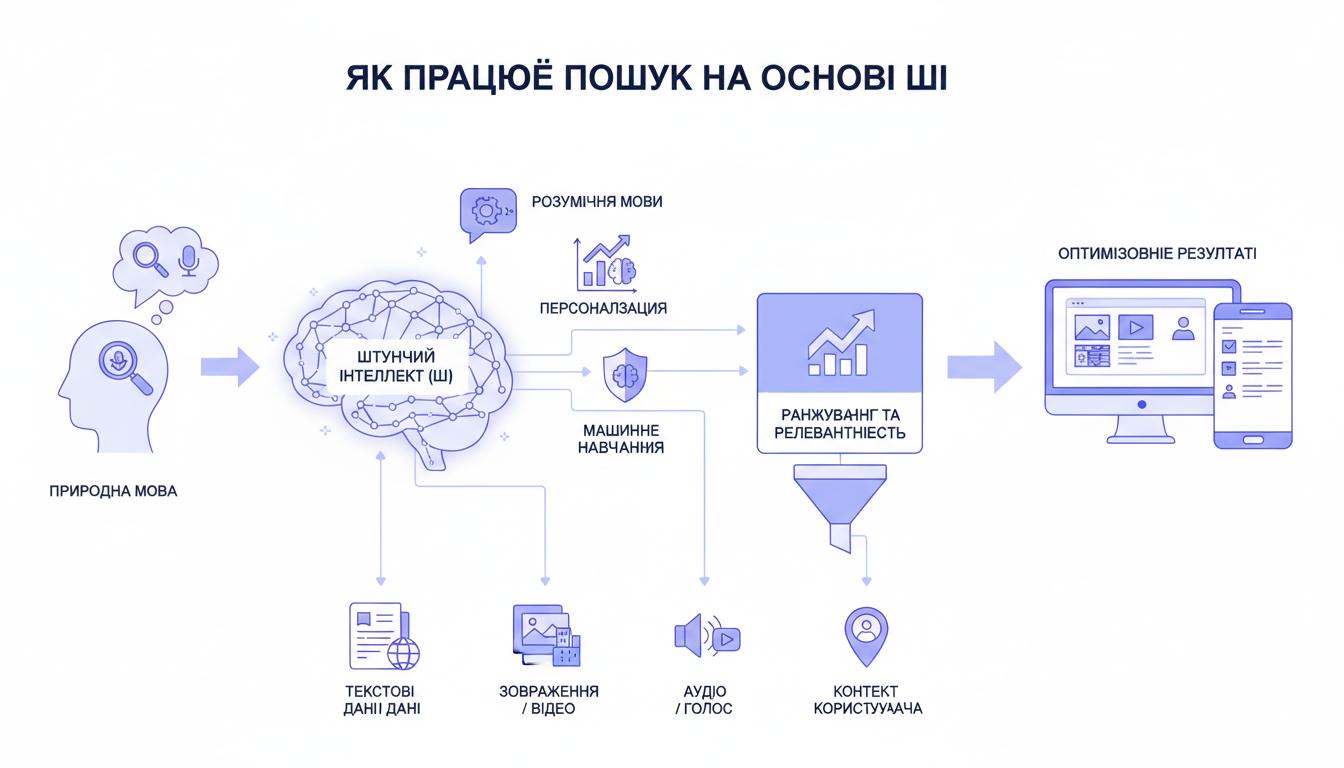
Коротка схема: від запиту до відповіді

Пояснити процес можна у кілька етапів: розпізнавання й розуміння запиту, пошук релевантних документів у індексі, оцінка відповідності й формування результатів. Кожен крок зараз підсилений моделями штучного інтелекту.
Ця схема працює як на великих пошукових платформах, так і на корпоративних або сайтових системах пошуку. Деталі можуть відрізнятись, але загальна логіка однакова.
Розпізнавання та розуміння запиту
Починається все з того, що система перетворює введений текст у внутрішнє представлення. Тут на допомогу приходять токенізація, нормалізація й лінгвістичний аналіз. Сучасні моделі працюють не лише зі словами, а з їхнім значенням у контексті.
Ключовий крок — визначення наміру користувача. Чи це інформаційний запит, чи комерційний намір, чи питання на кшталт «як зробити» — від цього залежить стратегія пошуку й формат відповіді. ШІ навчають на мільйонах прикладів, щоб прогнозувати найімовірніший намір.
Розпізнавання сутностей і наміру
Моделі витягують із запиту сутності: імена, місця, дати, назви продуктів. Це допомагає звузити коло пошуку й підказати, які джерела варто переглядати першочергово. Наприклад, у запиті «коли збирання яблук в києві» сутності — «яблука» і «Київ» — а намір — інформаційний.
На практиці я бачив, як точне витягування сутностей істотно скорочує час пошуку релевантних документів, особливо в нішевих базах знань.
Індексація: як зберігаються знання
Індексація — це не просто перелік URL і слів. Сучасні індекси зберігають множинні репрезентації контенту: традиційні зворотні індекси для ключових слів і векторні представлення для семантичного пошуку.
Векторні індекси дозволяють порівнювати запит і документи за смислом. Замість пошуку точних збігів система шукає найближчі по семантичному відношенню вектори, що дає відповіді на запити у вільній формі.
Технічні деталі індексації
Під час індексації текст розбивають на частини, генерують для них ембедінги й зберігають у спеціальних базах — векторних базах даних. Паралельно зберігаються метадані: заголовки, дати, автори, рейтинг довіри.
Добре продумана схема індексації дозволяє швидко комбінувати пошук по словах і векторах, що особливо корисно при гібридних підходах.
Векторний пошук і семантичне порівняння
Ключова ідея векторного пошуку — перевести запит і документи в числові вектори і знаходити найменшу відстань між ними. Це працює навіть коли запит і текст використовують різні слова для одного й того ж поняття.
Наприклад, запит «як лікувати головний біль» може знайти статтю, де говориться «засоби від мігрені», хоча прямих збігів слів немає. Так працює семантика на рівні значень, а не лише форми.
Порівняння методів
| Підхід | Переваги | Обмеження |
|---|---|---|
| Ключове слово | Швидко, просте кешування | Чутливе до формулювання, важко працює з синонімами |
| Векторний пошук | Розуміє сенс, стійкий до різних формулювань | Вимагає обчислювальних ресурсів і якісних ембедінгів |
Гібридні системи: найкраще з двох світів
Найефективніші рішення поєднують традиційний індекс ключових слів з векторним пошуком. Такий підхід дозволяє використовувати строгі фільтри й швидке сортування плюс семантичну релевантність.
Гібридні системи також дають можливість тонко налаштувати ваги: наприклад, віддавати пріоритет ключовим словам для комерційних запитів і векторній релевантності для інформаційних.
Оцінка релевантності і ранжування
Після того як знайдено кандидати, система оцінює їх релевантність. Тут працює безліч сигналів: якість контенту, авторитет джерела, поведінкові сигнали користувачів, відповідність наміру.
Штучний інтелект навчають поєднувати ці сигнали в єдину модель ранжування, яка прогнозує ймовірність того, що результат задовольнить користувача. Часто застосовують навчання з підкріпленням або learning to rank підходи.
Сигнали ранжування
- Семантична відповідність (векторна близькість).
- Якість та повнота контенту.
- Соціальний доказ і посилання.
- Поведінкові метрики: CTR, час на сторінці, показник повернення.
Пошук із підкріпленням контекстом: RAG і відповіді «як сервіс»
Коли потрібно не просто показати посилання, а згенерувати відповідь, використовують підхід Retrieval-Augmented Generation. Система шукає релевантні документи й підставляє їх до генеративної моделі для формування відповіді.
Такий механізм корисний у чат-ботах, техпідтримці й при побудові персоналізованих FAQ. Він поєднує довіру джерел із гнучкістю генерації природної мови.
Інфраструктура: швидкість і масштаб
Векторні пошуки потребують індексів, оптимізованих для швидкого знаходження найближчих сусідів. Для цього використовують спеціальні алгоритми і структури — HNSW, IVF, PQ. Вони зменшують час відповіді й зберігають точність.
У виробничих системах важлива горизонтальна масштабованість, балансування навантаження й кешування результатів. Латентність часто вимірюється в десятках мілісекунд, і це критично для користувацького досвіду.
Етика, приватність і безпека
Пошук може відкривати чутливу інформацію або підкреслювати упередження, закладені в навчальних даних. Тому важливо фільтрувати контент, мати прозорі політики і механізми редагування результатів.
Захист персональних даних вимагає анонімізації, контролю доступу й зваженого зберігання логів. Компаніям варто впроваджувати аудит моделі та моніторинг на предмет несподіваних або шкідливих відповідей.
Проблеми й обмеження
Моделі іноді дають правдоподібні, але хибні відповіді — явище «голосіння впевненістю». Також вони можуть бути чутливими до домішок у даних і погано пояснювати свої висновки.
Крім того, робота з багатомовністю і регіональними особливостями залишається складною. Потрібні окремі набори даних і тонке налаштування, щоб уникати погіршення якості для менш поширених мов.
Практичні поради для власників сайтів і SEO
Якщо ви прагнете, щоб ваш контент краще «розумівся» пошуковими системами на основі ШІ, почніть з чіткого структурування тексту: заголовки, метадані, семантичні блоки. Так моделі легше витягують сутності й контекст.
Орієнтуйтесь на повноцінні відповіді: статті, що охоплюють тему глибше й структуровано, частіше потрапляють у добірки або в сніпети з відповідями. Також варто оптимізувати швидкість завантаження й мобільну зручність.
Технічні кроки
- Додавати структуровані дані (schema.org) для явного опису сутностей.
- Забезпечити якісний семантичний HTML і доступні заголовки.
- Підтримувати канонічні URL і чисту карту сайту.
- Створювати FAQ і короткі відповіді, які легко використовувати в генеративних відповідях.
Як перевіряти ефективність пошукової системи
Оцінюйте точність і корисність результатів за метриками: precision, recall, MRR. Паралельно спостерігайте поведінкові метрики користувачів — CTR, час на сторінці, повернення за тією ж темою.
Не забувайте збирати якісний фідбек від реальних користувачів. Мене не раз виручав простий опитувач «Чи була відповідь корисною?» — він дає конкретні сигнали для покращення моделей.
Приклади застосувань у реальному житті
Семантичний пошук у корпоративних базах знань дозволяє працівникам швидше знаходити стандарти й процедури. У медичних системах ШІ допомагає підбирати релевантні дослідження за симптомами та історією хвороби.
У сфері електронної комерції поєднання векторного пошуку й фільтрів підвищує конверсії: користувачі отримують релевантні пропозиції навіть при неточних запитах або фото-запитах.
Майбутні тренди
Далі ми побачимо глибшу інтеграцію мультимодальних моделей, здатних працювати з текстом, зображеннями й аудіо одночасно. Це відкриє можливості для пошуку за фото або голосом із семантичним розумінням.
Також зріст локальних генеративних моделей й оптимізація для edge-пристроїв дозволять робити приватніші рішення без передачі даних в хмару.
Мій досвід: впровадження семантичного пошуку
Кілька років тому я працював над внутрішньою системою пошуку для великої компанії. Ми поєднали класичний індекс і векторний шар, що дозволило значно зменшити час на пошук потрібних інструкцій для техпідтримки.
Найскладнішим виявилося налаштування вагів і баланс між релевантністю та швидкістю. Експерименти на реальних запитах і тісний контакт з кінцевими користувачами дали найбільше покращень.
Коли варто впроваджувати пошук на основі штучного інтелекту
Інвестиція в семантичний пошук виправдана, коли у вас є великий незструктурований корпус контенту або вимога давати точні відповіді на складні запити. Для невеликих сайтів базовий keyword-пошук іноді достатній.
Я рекомендую починати з гібридного підходу: додайте векторний шар для ключових розділів, а не для всього контенту одразу. Це дозволяє поступово оцінити вигоди й оптимізувати витрати.
Короткий чекліст для запуску
- Оцініть обсяг даних і тип запитів користувачів.
- Виберіть модель для ембедінгів з урахуванням мови та тематики.
- Побудуйте векторний індекс і налаштуйте гібридну логіку.
- Впровадьте моніторинг і збір фідбеку від користувачів.
- Поступово оптимізуйте метрики ранжування та продуктивність.
FAQ

1. Чим векторний пошук відрізняється від звичайного пошуку за ключовими словами?
Векторний пошук порівнює семантичні уявлення тексту, тому знаходить документи за змістом, навіть якщо слова відрізняються. Класичний пошук орієнтований на точні збіги слів і фраз.
2. Які моделі краще використовувати для створення ембедінгів українською мовою?
Підбирайте моделі, які були натреновані або донавчені на текстах українською. Для багатомовних задач підходять сучасні трансформери з підтримкою мови, а для вузьких доменів корисне донавчання на вашому корпусі.
3. Чи можна поєднати генерацію відповідей і пошук у реальному проєкті?
Так. Підхід Retrieval-Augmented Generation дозволяє спочатку знайти релевантні джерела, а потім використовувати їх як контекст для генеративної моделі. Це підвищує достовірність відповідей.
4. Які основні ризики при впровадженні таких систем?
Ризики включають витік персональних даних, упередження в навчальних даних і хибні відповіді моделями. Необхідні аудит, фільтри і політики обробки даних.
5. Як виміряти, що пошук став кращим після впровадження ШІ?
Порівнюйте метрики точності (precision, MRR), а також поведінкові індикатори — CTR, час на сторінці, показник повернення. Також корисні опитування користувачів і A/B тестування.
Якщо вам цікаво більше практичних кейсів і покрокових гайдів, заходьте на наш сайт https://modgallery.com.ua/ і читайте інші матеріали. Там є статті про налаштування індексів, вибір моделей і приклади оптимізації продуктивності.

